
![]() This post is older than a year. Consider some information might not be accurate anymore.
This post is older than a year. Consider some information might not be accurate anymore. ![]()
Used: logstash v6.5.4 elasticsearch v6.5.4 kibana v6.5.4
This blog post is a little treat for all geeks. In short, we will introduce logstash to ingest data into Elasticsearch. The occasion is to celebrate today the Lunar New Year or Chinese New Year. 2019 is the Year of the Pig. In Chinese culture, pigs are the symbol of wealth. Their round faces and big ears are signs of fortune as well. The common belief is that pigs are blessed with luck and have a beautiful personality. See below the fortune output for the year of the pig.
Real and digital fortune cookies
If it comes to luck, there is a great misconception about fortune cookies in the Asian culture. Fortune cookies are often served as a dessert in Chinese restaurants in the United States and other Western countries but are not a tradition in Asia. A served cookie contains a fortune with some wisdom or vague prophecy. Since Unix, the fortune application does the same on the terminal. Fortune displays a random message from a database of quotations. I have created a database set for geeks, which holds some favourite tweets from Programming Wisdom. See below a quote.
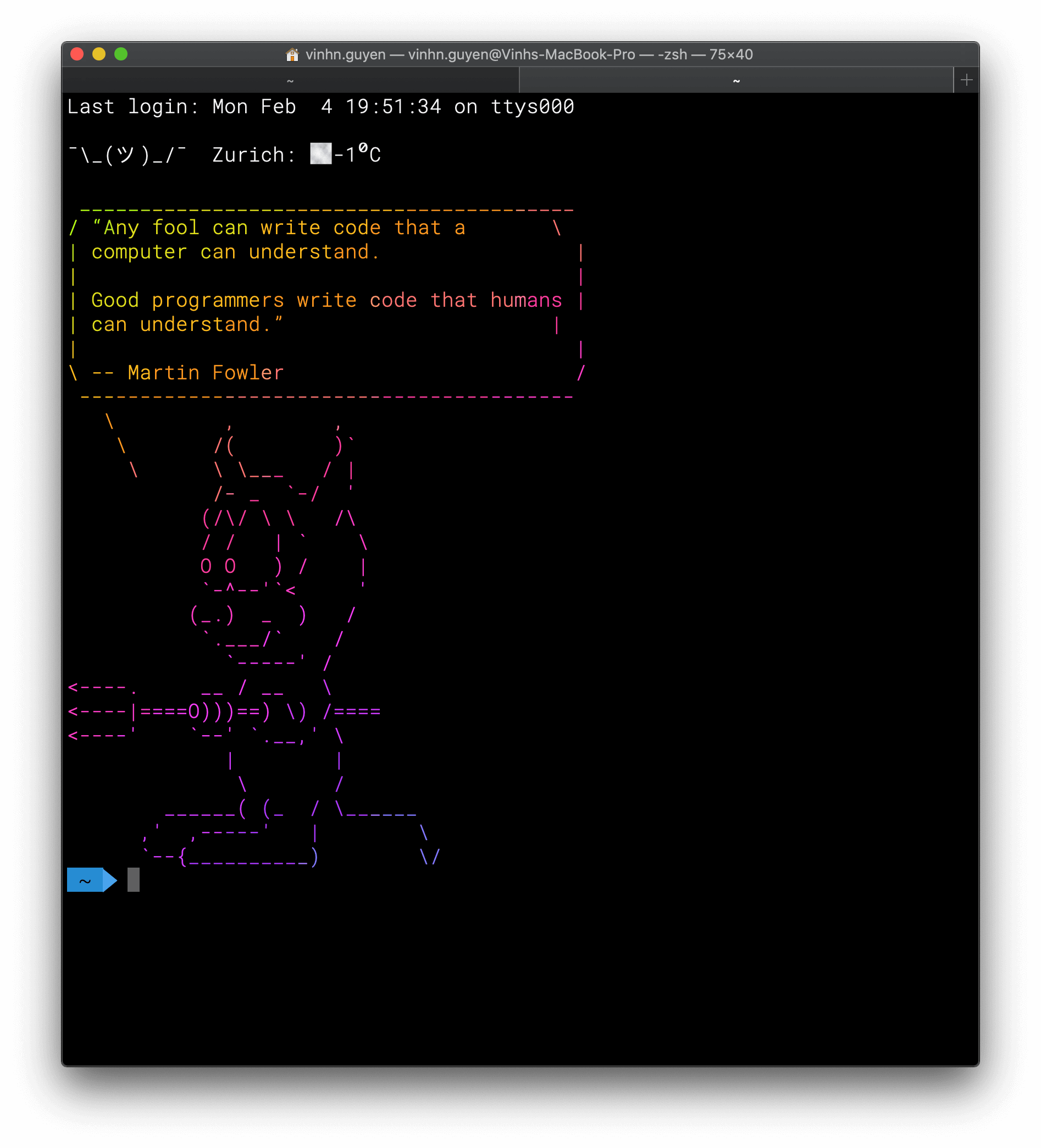
Example Data
The database for fortune is a simple text file, which has these format rules:
- Each entry starts with
%. - Each entry must end with a newline.
We take a small data excerpt for our logstash demo:
Elasticsearch Storage
Logstash is like a swiss knife. You can pre-process nearly any kind of data for Elasticsearch. In Elasticsearch, we want to store the content and the person. Having the data in Elasticsearch, we can search for wisdom if needed for example in a presentation. We could tweak the text analysing, but we are going to deal with that in a separate future blog post.
To store the data, you can provide logstash with an index template.
We choose to store analysed text only for the quotes and for the person we want the default multi-field approach. We may search for names but might also want to do aggregation on persons.
Logstash configuration
Logstash allows to have three sections:
- input => describes the data flying in
- filter => process the data, e.g. parse (grok), clean up
- output => writes the processed data to an output destination
input
As input, we take the file. We apply the multiline codec and configure to treat each line, that belongs to the beginning entry with % as one event.
filter
The filter section contains the commands to clean up the data and separate them into the fields quote and person.
output
After the filter section, Logstash returns, for instance, this data:
{
"tags" => [
[0] "multiline"
],
"path" => "/home/vinh/development/projects/geek-fortune-cookies/databases/programming-wisdom",
"@version" => "1",
"@timestamp" => 2019-02-04T21:47:54.641Z,
"quote" => "\"A program is like a poem: you cannot write a poem without writing it.\" ",
"host" => "docker-logstash",
"person" => "E.W Dijkstra"
}
We use Elasticsearch for storage, so the output uses the elasticsearch output plugin.
The noteworthy part is that we provide the template options, to tell Elasticsearch how to store the data.
In the end, you will receive this output as displayed in Kibana.

Summary
As demonstrated, Logstash is a powerful tool to deal with data in a challenging format. The fortune database for geeks was an example. The configuration is challenging itself. With proper help, guidance and patience you can accomplish to get almost any data into Elasticsearch. We wish you a happy and fortunate year of the pig!
