![]() This post is older than a year. Consider some information might not be accurate anymore.
This post is older than a year. Consider some information might not be accurate anymore. ![]()
My test cluster health was yellow. The X-Pack Monitoring pointed to some indices, which were yellow.
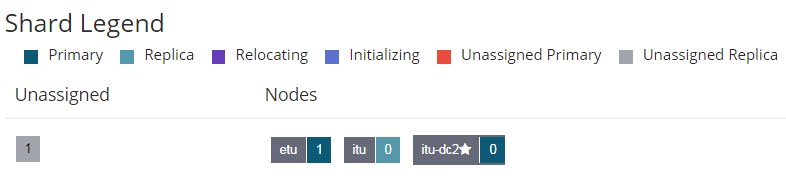
If I check the shards on a specific index
GET _cat/shards/ep2-2017.10.15?V
Result
index shard prirep state docs store ip node
ep2-2017.10.15 1 p STARTED 453095 236.6mb 10.22.62.135 etu
ep2-2017.10.15 1 r UNASSIGNED
ep2-2017.10.15 0 p STARTED 454530 237.2mb 10.22.191.23 itu-dc2
ep2-2017.10.15 0 r STARTED 454530 237.2mb 10.22.62.130 itu
If you try to allocate the unassigned replica:
POST /_cluster/reroute
{
"commands": [
{
"allocate_replica": {
"index": "ep2-2017.10.15",
"shard": 1,
"node": "etu-dc2"
}
}
]
}
We get an extended error reason.
{
"error": {
"root_cause": [
{
"type": "remote_transport_exception",
"reason": "[itu-dc2][10.22.191.23:9300][cluster:admin/reroute]"
}
],
"type": "illegal_argument_exception",
"reason": "[allocate_replica] allocation of [ep2-2017.10.15][1] on node {etu-dc2}{aeT1BPu2SjW1g3A18RnuTA}{QxY1ImcVQuuFFGjE31bOzw}{mtlplfohap05}{10.22.191.14:9300}{ml.max_open_jobs=10, rack=with-nas, box_type=hot, ml.enabled=true} is not allowed, reason: [YES(shard has no previous failures)][YES(primary shard for this replica is already active)][YES(explicitly ignoring any disabling of allocation due to manual allocation commands via the reroute API)][NO(target node version [5.6.1] is older than the source node version [5.6.3])][YES(the shard is not being snapshotted)][YES(node passes include/exclude/require filters)][YES(the shard does not exist on the same node)][YES(enough disk for shard on node, free: [183.5gb], shard size: [0b], free after allocating shard: [183.5gb])][YES(below shard recovery limit of outgoing: [0 < 2] incoming: [0 < 2])][YES(total shard limits are disabled: [index: -1, cluster: -1] <= 0)][YES(allocation awareness is not enabled, set cluster setting [cluster.routing.allocation.awareness.attributes] to enable it)]"
},
"status": 400
}
Check for the NO condition:
[NO(target node version [5.6.1] is older than the source node version [5.6.3])]
After I checked my nodes, I saw there was a partial cluster upgrade.
GET /_cat/nodes?v&h=version,name,jdk
version name jdk
5.6.1 itu 1.8.0_141
5.6.1 etu-dc2 1.8.0_141
5.6.3 etu 1.8.0_141
5.6.3 dev 1.8.0_141
5.6.1 itu-dc2 1.8.0_141
After the upgrade everything worked fine and the cluster health was back to green.
