![]() This post is older than a year. Consider some information might not be accurate anymore.
This post is older than a year. Consider some information might not be accurate anymore. ![]()
Used: elasticsearch v7.3.0 kibana v7.3.0 logstash v7.3.0
This article is the beginning of our Elastic Stack article series, that explains the Elastic Stack for Beginners and curious people. I use football data as the basis for our demonstrations and examples for three reasons. The first reason is that the football (soccer) season starts again this weekend. I live in the city of the current Swiss Football champion (Bsc Young Boys). I want them to succeed again this season. The final reason is my little nephew. On my summer vacation visit, my nephew asked me what I do for a living in Switzerland: Software Engineering and Architecture for Distributed Computing. That was too abstract or vague for him. Kids are naturally curious. He is a smart kid, so he rephrases the question of what kind of products or tools I use for work. It came down to the Elastic Stack.
The Elastic Stack is a fast-forwarding technology. It is challenging to keep up the pace. My advice to all beginners: Focus on the essential concepts that matter, not on every implementation detail. Useful concepts are going to outlast. I use the Feynman Technique to explain it to my nephew. With the help of football data, I have successfully explained the Elastic Stack to a 12-year-old.
Relatable Data for the Feynman Technique
Richard Feynman was a Nobel prize-winning physicist, for his ability to relay complex ideas to other persons in simple, intuitive ways. The Feynman Technique is a method for learning or reviewing a concept quickly by explaining it in plain, simple language. While you’re working through the Feynman Technique for any given idea, it can be useful to pretend that you’re explaining that concept to a child or a layman. In my case, I don’t have to pretend ;-).
If kids are asking, they are thinking that work is fun and the Elastic Stack is a game. He is not far away from the truth. My work with the Elastic Stack is fun. Since he is a football (soccer) player, I explained the capabilities of the Elastic Stack with data of one of his favourite games: FIFA Soccer 2019.
It is also an excellent method, to use data, that he can relate too. Football or soccer is popular, so I reuse the FIFA 2019 football data in most of my training sessions and live demos. Useful relatable data and examples always enhance the Feynman technique. A positive association has a significant impact on the receiving end. It is more exciting and more comfortable to follow and remember.
Children are quick to point out their confusion. If the explanation lacks clarity or has gaps, it is the opportunity to improve your description. This will boost your own understanding. Do not make a mistake to treat your peers like children. Always assume people lack experience and knowledge, not intelligence. In the next series, we will demonstrate the Elastic Stack capabilities with football data.
Data Source
The dataset is from Kaggle and contains over 18k+ football player information. In this section, you will learn how to import that data with Logstash into Elasticsearch to follow the examples or reuse it for your own learning or training sessions.
Document and field modelling is an essential basis for your data exploration. We select only a small subset of the data for our introduction. It gives us an idea about the data and how to treat them in Elasticsearch.
- The Elasticsearch Type column reflects the field type in Elasticsearch.
- The Action column describes the action for Logstash.
Let us look into a fragment of the player profile data for Lionel Messi:
| Column | Example Value | Description | Elasticsearch Type | Action |
|------------------|------------------------------------------------|------------------------------------|--------------------|----------|
| | 0 | row number | | drop |
| ID | 158023 | unique id for every player | internal | |
| Name | L. Messi | name | multi-field | |
| Age | 31 | age | short | |
| Photo | https://cdn.sofifa.org/players/4/19/158023.png | url to the player's photo | keyword | |
| Nationality | Argentina | nationality | keyword | |
| Flag | https://cdn.sofifa.org/flags/52.png | url to players's country flag | keyword | |
| Overall | 94 | overall rating | short | |
| Club | FC Barcelona | current club | keyword | |
| Club Logo | https://cdn.sofifa.org/teams/2/light/241.png | url to club logo | keyword | |
| Value | €110.5M | current market value | keyword | convert |
| Release Clause | €226.5M | release clause value | keyword | convert |
The full data definition and import configuration for this article are available at this GitHub repository. This repository contains a docker folder, with a setup for Elasticsearch. You can start Elasticsearch and Kibana with this command in the docker folder.
docker-compose up
If you need more information on how to manage Elasticsearch and Kibana with Docker, please read our previous article: Manage multi-container setups with Docker Compose.
Logstash Import
The data is in a CSV (comma-separated values) format. Following Logstash configuration reads the data from the file. Change the configuration values to your needs.
input {
file {
path => "/opt/data/data.csv"
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
csv {
columns => [ .. ]
# index template defines types
remove_field => [ "message", "bla" ]
}
}
output {
stdout { codec => "dots" }
elasticsearch {
hosts => ["kick-es:9200"]
index => "fifa-2019"
document_id => "%{id}"
template => "/usr/share/logstash/pipeline/index-template.json"
template_name => "fifa"
template_overwrite => true
}
}
We can use the csv filter in Logstash to parse the content to its respective fields. The order of the columns is essential.
- You can drop columns or unwanted data in the
remove_fieldlist. - The output section contains the output target to Elasticsearch.
- Our docker container name for Elasticsearch is
kick-es. - Important is to pass the template to make Elasticsearch uses our field types.
You can import the data by running logstash with the configuration.
$LOGSTASH_HOME/bin/logstash -f fifa-2019.conf
The import stops after 18206 records. Check if the data was successfully imported in index fifa-2019.
Either with the Kibana Console
GET fifa-2019/_count
or with a curl in the terminal.
curl -XGET "http://kick-es:9200/fifa-2019/_count"
If you see this result, the data is imported.
{
"count" : 18206,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
Logstash is tailing the input file for new content, so it will not stop on its own. You can quit Logstash with
The Power of Visualisation
Importing the data with Logstash into Elasticsearch is the first step. To explain the data to my nephew, I use Kibana. Kibana is the window or UI to explore data with Elasticsearch. If you started the docker setup, you could access Kibana on the default address.
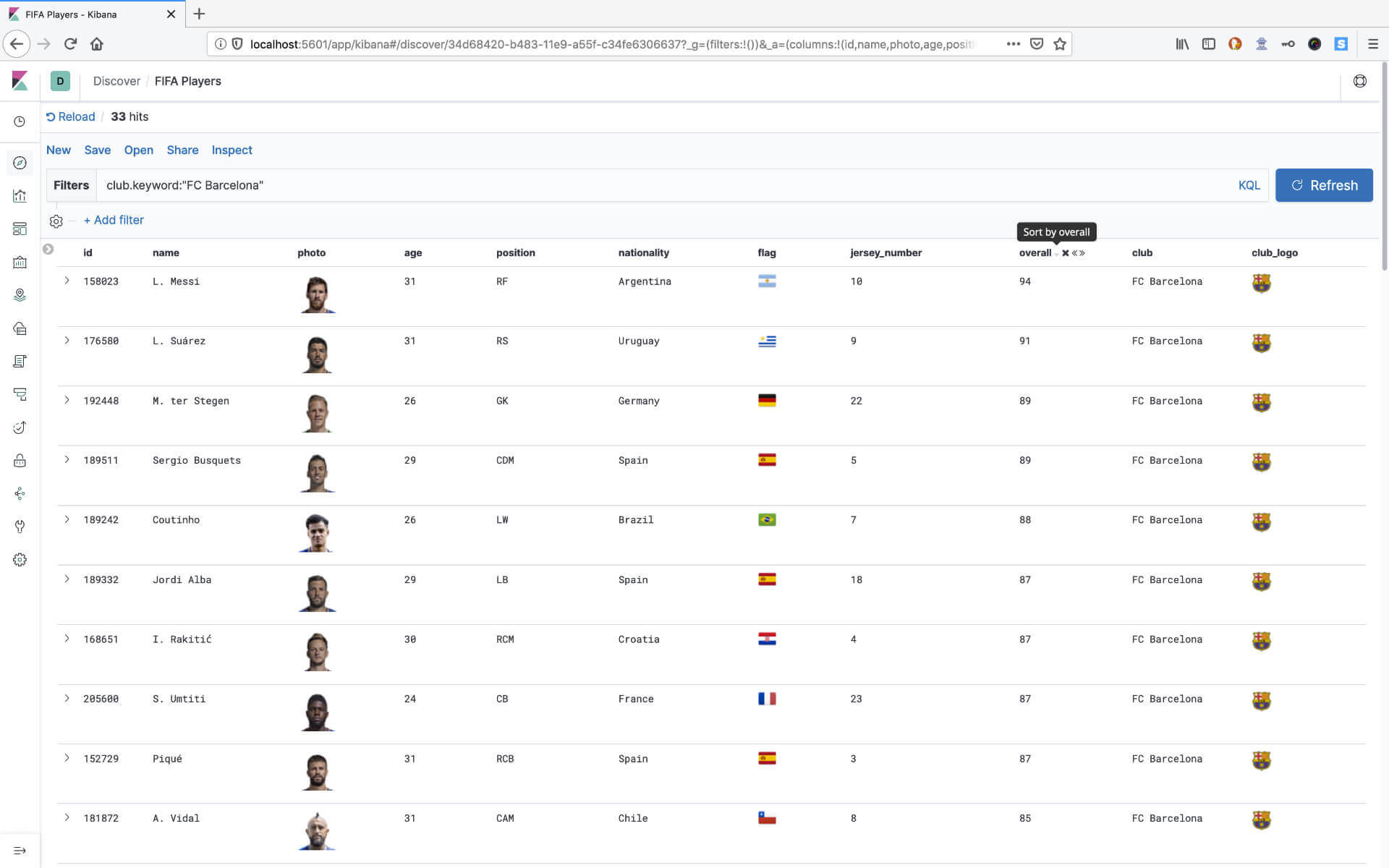
Visualisation is a powerful must. One picture can say more than 1000 words. At first, I demonstrate that Elasticsearch is about search.
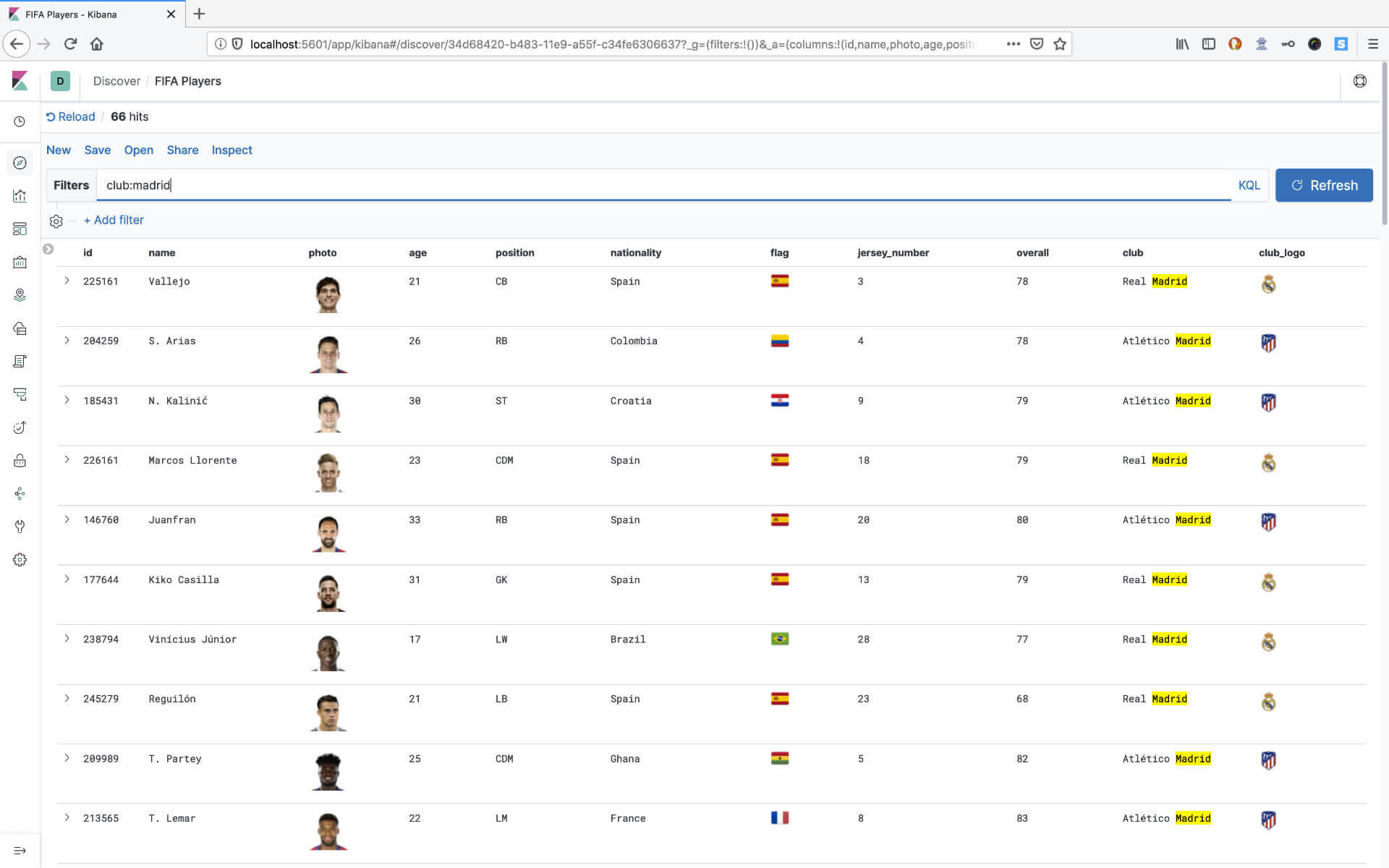
If you search for the club madrid, you get the results for Real and Atlético Madrid.
If you want to see results only for Real Madrid, you start typing rea and see a list of autocomplete suggestions.
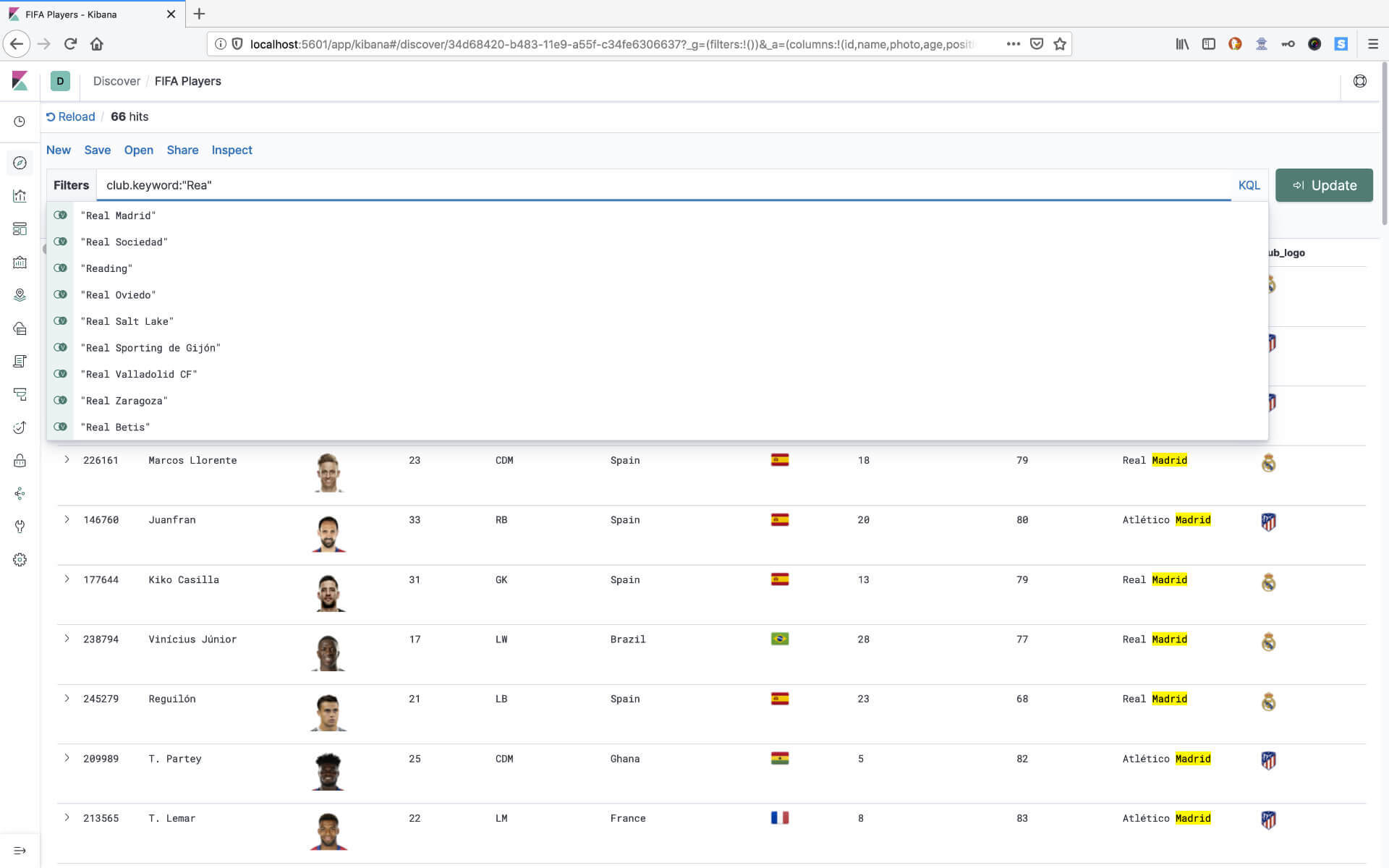
Seeing this in action, was a great help for my nephew in understanding my work, making complicated things simple.
Summary
- Football is coming home or back this weekend!
- You have learned that the Feynman Technique exists.
- It can help you to learn anything faster and more efficiently.
- Using useful relatable data enhances the technique.
- We are using Logstash to ingest that data into Elasticsearch for further usage.
- Kibana is the UI for Elasticsearch.
- Elasticsearch is about search.
In the next article, we are going to take the first baby steps to explain how to setup Kibana for data exploration for the football data. The outcome will be this: